Ensemble Attacks
This section has a series of coding problems using PyTorch. As always, we highly recommend you read all the content on this page before starting the coding exercises.
One interesting feature of adversarial images is that they often "transfer" to other models. By transfer, we mean that we can optimize an adversarial example on one model, and use it to successfully attack an entirely different model. We can see an analogous quality for the adversarial suffix jailbreaks on language models which you will explore in the GCG section later in this course.
Targeted vs Untargeted Transfers
Finding targeted adversarial examples that transfer is much harder than finding untargeted examples that transfer (Liu et al., 2017). This is because it is much easier to drive the loss up when there isn't a constraint on the exact direction the loss should be moving upwards. In other words, the loss landscape for predicting a singular target class is less generous than the landscape for predicting any class other than the clean label. Think about a target containing all classes. If you are trying to shoot an arrow at the below target and you are trying to hit anything but the correct class, it is easy. If you are trying to hit a specific incorrect class however, the task becomes much more difficult.
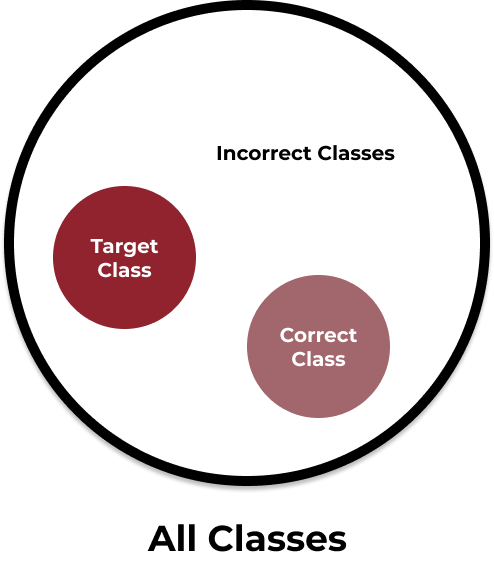
Fig. 1
Mental model for thinking of targeted vs untargeted attacks
Threat Model for Transferability
Transferable adversarial images and jailbreaks are interesting, but it may not be entirely obvious why they are important for security. One reason is that in many cases, an attacker may want to attack a model that is secured behind an API. In other words, the attacker doesn't have white-box access and therefore cannot run an algorithm like PGD or CW. They may also not be able to query the model repeatedly without arousing suspicion or incurring high API costs. One solution to this issue is to attack a white-box model for free using as many iterations as the attacker would like, and then hope that the attack transfers. When a white-box model is used in this way, you may hear it referred to as a "surrogate model." Because there are plenty of open source models available for download, there are plenty of surrogate models to choose from, making these transfer attacks practical to execute.
Improving Transferability
One problem with attacks that rely on transferability is that they aren't reliable. Sometimes the transfer works, but other times it doesn't and in practice, it is difficult to know which model is a good choice to use as a surrogate. One solution to this problem is to use a diverse selection of surrogate models rather than to choose one and hope for the best. These kinds of attacks are called ensemble attacks (Liu et al., 2017).
In an ensemble attack, you choose models and assign each a weight for how much that model should influence the attack loss. Traditionally , so you can think about the total loss as being shared between each model. If is our clean image and is our adversarial perturbation, let be the attack loss for a specific model . You can think of as being similar to the function from the Carlini-Wagner attack in a previous section. Let be some distance metric such as an norm. Then we try to find such that it minimizes the following:
In the original paper, the authors use cross entropy loss for but other attacks that are conceptually similar can use other losses.
If you have completed the coding exercises in the previous two sections you will probably notice that the optimization above is more similar to a Carlini-Wagner attack than PGD. For simplicity, we diverge from the original paper a bit in our coding exercises where you will complete something more similar to PGD. This involves less code and no hyperparameters, but you are welcome to try a version more faithful to the original paper if you are interested.