As you might've noticed, PAIR and TAP are two prompt-level jailbreaking algorithms that operate primarily by simply asking one LLM to jailbreak another. Here, we'll introduce two slightly more advanced prompt-level jailbreaking algorithms: GPTFuzzer and AutoDAN. (Interestingly, both of these algorithms take inspiration for areas outside of machine learning!)
GPTFuzzer
Fuzzing is a technique originating form software testing that involves giving random inputs to a piece of software to uncover possible bugs and vulnerabilities. As explained by Yu et al. (2024), the process generally involves four steps:
Initializing the seed pool, or the collection of inputs that can be sent to the program.
Selecting a seed (this sometimes involves algorithms to select seeds more likely to break the software).
Mutating the seed to generate a new input.
Send the new input to the program.
Through the GPTFuzzer algorithm, Yu et al. (2024) ports this software-originating red-teaming method to the domain of LLMs, using manually-crafted jailbreaks as the seed pool. In fact, the algorithm essentially mirrors the four steps given above.
Algorithm: GPTFuzzerData: Human-written jailbreak templates from the InternetResult: Discovered jailbreaksInitialization:Load initial datasetwhile query budget remains and stopping criteria unmet doseed←selectFromPool()newTemplate←applyMutation(seed)newPrompt←combine(newTemplate, target question)response←queryLLM(newPrompt)if successfulJailbreak(response) thenRetain newTemplate in seed pool
There are two main novelties of this algorithm which we'll look into: seed selection and prompt mutation.
Seed Selection (MCTS-Explore)
A popular choice among software fuzzers is using the Upper Confidence Bound (UCB) score for seed selection. Each seed's UCB score is given by
score=rˉ+cn+12ln(N).
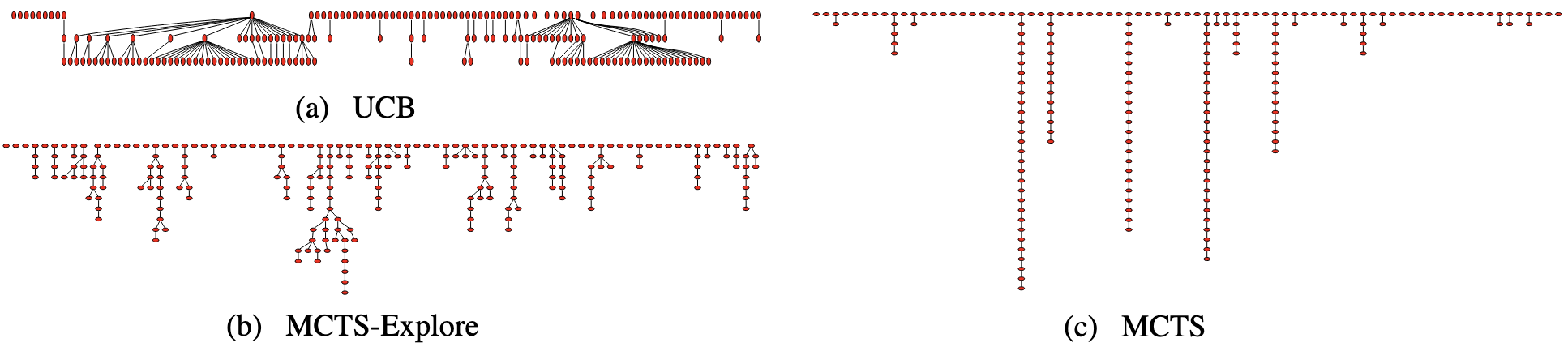
Here, rˉ is the seed's average reward, N is the number of iterations, and n is the seed's selection count. Essentially, the rˉ term favors using seeds that have previously been successful, whereas n+12ln(N) favors seeds that haven't been selected, with c serving to balance the two objectives. Unfortunately, the UCB strategy has the drawback of getting stuck in local minima. To combat this problem, Yu et al. (2024) created a modified version of Monte-Carlo tree search named MCTS-Explore.
Algorithm: MCTS-ExploreInput: Root node root, early-termination probability p,seed set SInput: reward penalty α, minimal reward βInitialize:for each seed∈S doroot.addChild(seed)path←[root]node←rootwhile node is not a leaf dobestScore←−∞bestChild←nullfor each child in node.children doscore←child.UCBscoreif score > bestScore thenbestScore←scorebestChild←childnode←bestChildappend(path,node)if random(0,1)<p then breaknewNode←Mutate(last(path))reward←Oracle(Execute(newNode))if reward>0 thenreward←max(reward−α⋅length(path),β)path[-1].addChild(newNode)for each node in path donode.visits←node.visits+1node.r←node.r+rewardnode.UCBscore←node.visitsnode.r+cnode.visits2ln(parent(node).visits)
There might look like a lot going on here, but the core ideas are fairly simple. We first add all the initial seeds as the "children" of the root node in the tree. Next, inside the while loop, we travel down the tree, each step moving to the child with the highest UCB score. To ensure that non-leaf prompts also get selected, there's a probability p of stopping at any non-leaf node. After constructing our path, we mutate the selected prompt and get a reward score for the mutation. We then modify the reward amount if the mutant was successful based on the parameters α and β; α penalizes scores that come from longer paths to encourage a wider breadth of exploration, whereas β serves as a "minimum" score to prevent successful prompts with high length penalties from getting ignored. Finally, we add our new node as a child to its original node then update the scores in the path accordingly.
Fig. 1 Visualization of UCB, MCTS, and MCTS-Explore Algorithms, from Yu et al. (2024a)
Mutation and Reward Scoring
In the MCTS-Explore algorithm, we Mutate() the existing seeds to get new ones, but how exactly does this work? First, Yu et al. (2024b) covers 5 main mutation methods: generate, crossover, expand, shorten, and rephrase. Succinctly, generate maintains style but changes content, crossover melds multiple templates into one, expand augments existing content, shorten condenses existing content, and rephrase restructures existing content. The first two serve to diversity the seed pool, whereas the last 3 refine existing templates. All of these operations are done with an LLM (hopefully, you're noticing a trend in the prompt-level jailbreak techniques here). To score the jailbreak prompts, the authors utilize a fine-tuned RoBERTa model that returns 1 in the case of a successful jailbreak and 0 otherwise.
That's about all there is to GPTFuzzer! Interestingly, GPTFuzzer's attacks were able to transfer very well, with an ASR against the Llama-2 herd at or above 80%, although its ASR against GPT-4 was only 60%, even when starting with the five most effective manually-crafted jailbreaks.
Similarly to how GPTFuzzer pulled from software testing to introduce fuzzing to LLMs, Liu et al. (2024) used a hierarchical genetic algorithm to automatically jailbreak LLMs in their AutoDAN algorithm.
Genetic Algorithms
Genetic algorithms are a kind of algorithm drawing from evolution and natural selection. They start with a population of candidate solutions, to which certain genetic policies (e.g. mutation) are applied to generate offspring. Then, a fitness evaluation is applied to the offspring to determine which offspring are selected for the next iteration. This process continues until some stopping criteria is reached.
Population Initialization & Fitness Evaluation
Similarly to GPTFuzzer, the initial population begins with a successful manually-crafted jailbreak prompt which is then diversified into a number of prompts by an LLM. To evaluate the fitness of each prompt, Liu et al. (2024) adopts the GCG negative log likelihood loss from Zou et al. (2023).
Genetic Policies
AutoDAN employs a two-level hierarchy of genetic policies to diversify the prompt space, consisting of a paragraph-level policy and a word-level policy.
In the paragraph-level policy, we first let the top αN elite prompts through to the next round without change. To select the remaining N−αN prompts, we apply the softmax transformation to each prompt's score to get a probability distribution, from which we sample the N−αN prompts. For each prompt, we perform a crossover between prompts at various breakpoints with probability pcrossover, then mutate the prompts with probability pmutation (once again with an LLM). These offspring are then combined with the initial elite prompts to get the next iteration.
In the sentence-level policy, we first apply the prompt's fitness score to every word, averaging the scores of words that appear across different prompts. We also average the word's score with the previous iteration's score of the word to incorporate momentum and reduce instability. Next, we filter out various common words and proper nouns to achieve a word score dictionary. Finally, we swap the top-K words in the dictionary with their near synonyms in other prompts.
Stopping Criteria
The AutoDAN algorithm continues to run until a set number of iterations is reached or no word in a set of refusal word Lrefuse is detected. The full algorithm is below (although it is relatively informal due to the lengthiness of many of the described required steps).
Algorithm: AutoDAN Hierarchical Genetic Algorithm (HGA)Input: Initial prompt Jp, Refusal lexicon Lrefuse, Population size N,Input: elite fraction α, crossover probability pc,Input: mutation probability pm, top-K words KOutput: Optimal jailbreak prompt JmaxInitialize: Population P←DiversifyWithLLM(Jp,N)while response contains words in Lrefuse and iterations not exhausted dofor i=1,…,Tsentence doEvaluate fitness score for each individual J∈PW←CalculateMomentumWordScores(P)P←SwapTopKSynonyms(P,W,K)for j=1,…,Tparagraph doEvaluate fitness score for each individual J∈PPelite←SelectTopPrompts(P,αN)Pparent←SampleFromDistribution(P,N−αN)Poffspring←∅for each Jparent∈Pparent doJcrossed←Crossover(Jparent,Pparent,pc)Jmutated←MutateWithLLM(Jcrossed,pm)Poffspring←Poffspring∪{Jmutated}P←Pelite∪PoffspringJmax←J∈Pargmax(Fitness(J))return Jmax
Similarly to GPTFuzzer, AutoDAN performed very well against Vicuna (ASR > 97%) and decently well against Llama-2 and GPT-3.5-Turbo (ASR ~65%). Interestingly, though, AutoDAN had an ASR on GPT-4 of less than 1%. Additionally, the authors noted that the jailbreaks generated by AutoDAN are "stealthy"; unlike GCG, they do note have high perplexity and can thus bypass naive perplexity filters.
A Fair Fight?
Liu et al. (2024) also noted that AutoDAN wall-clock time cost was equivalent or better than GCG's, which, when combined with its ability to evade perplexity filters, makes it seem like the unequivocally best choice. However, Confirm Labs again makes an insight that these comparisons aren't apples-to-apples. While the authors ran GCG on a single NVIDIA A100, their AutoDAN algorithm involves making dozens if not hundreds of API calls to GPT-4 (Straznickas et al., 2024). Thus, keep in mind that even if these prompt-based attacks prove to be more effective than GCG, if they rely on LLM calls, they're likely much less efficient.
Liu, X., Xu, N., Chen, M., & Xiao, C. (2024). AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models. International Conference on Representation Learning, 2024, 56174–56194.
Straznickas, Z., Thompson, T. B., & Sklar, M. (2024, January 13). Takeaways from the NeurIPS 2023 Trojan Detection Competition. https://confirmlabs.org/posts/TDC2023.html
Yu, J., Lin, X., Yu, Z., & Xing, X. (2024a). {\vphantom}LLM-Fuzzer\vphantom{}: Scaling Assessment of Large Language Model Jailbreaks. 33rd USENIX Security Symposium (USENIX Security 24), 4657–4674.
Yu, J., Lin, X., Yu, Z., & Xing, X. (2024b). GPTFUZZER: Red Teaming Large Language Models with Auto-Generated Jailbreak Prompts. arXiv. https://doi.org/10.48550/arXiv.2309.10253
Zou, A., Wang, Z., Carlini, N., Nasr, M., Kolter, J. Z., & Fredrikson, M. (2023). Universal and Transferable Adversarial Attacks on Aligned Language Models. arXiv. https://doi.org/10.48550/arXiv.2307.15043