Introduction to LLMs
This section has a series of coding problems using PyTorch. As always, we highly recommend you read all the content on this page before starting the coding exercises.
Overview
While this course assumes some background in machine learning, we do not expect all users to have hands-on experience with running, fine-tuning, and jailbreaking LLMs. To fill this gap, this document provides basic background on LLMs, along with a list of resources for further exploration.
What You Need to Know
The transformer architecture was introduced by Vaswani et al. (2017) for language translation. Since then, this architecture has been adapted for more general language modeling and underpins almost all LLMs developed today.
While the transformer architecture is incredibly interesting and well-designed, understanding it at a low level won't be necessary for our purposes. We want you to learn where the field is at and how attacks and defenses work. To this end, you will need to understand how to pass input into a transformer, parse its output, and calculate loss, but not how to build one from scratch.
We do not claim that having a lower-level understanding of models cannot motivate better attacks or defenses. In fact, we are cautiously optimistic about approaches that leverage findings from mechanistic interpretability for robustness. These directions, however, remain speculative and are for the most part outside the scope of this course.
Tokens
You are likely already familiar with the fact that LLMs predict the next token given its input. But what is a token?
What is or isn't a token depends on the model you are working with. In general, tokens are small chunks of text that appear frequently in the training data. They don't always correspond to full words. For example, the GPT-2 tokenizer you will be working with tokenizes the string "Hello there gpt-2!" as follows:
Input >>> Hello there gpt-2!
Tokens >>> ['Hello', ' there', ' g', 'pt', '-', '2', '!']
Negative Log Likelihood
Negative Log Likelihood (NLL) is a measure of loss we'll touch on often throughout the rest of this course. At a high level, minimizing this loss maximizes the probability that an LLM assigns to its training data. In the coding exercises, you will implement NLL loss on GPT-2 (Radford et al., 2019). To prepare you for these exercises, however, we will give a high-level overview of how this is done.
Every language model has a vocabulary, which is the set of all possible tokens that a model is able to input and output. When you pass a string of text to a language model, you will get an output assigning some real-numbered value to every token in the vocabulary; these values are called logits. We then apply the softmax operation over the logits, which turns each of these real-numbered values into a number between 0 and 1. The equation below gives the softmax value for token in the output when there are items in the vocabulary.
One helpful feature of this operation is that . This means that we can treat the softmax outputs as a probability distribution, where each value represents the probability the model assigns to each potential token.
A useful loss should maximize the probability of the correct token. The first step we take to accomplish this is computing the log of the probability of the correct token. The graph below shows for .
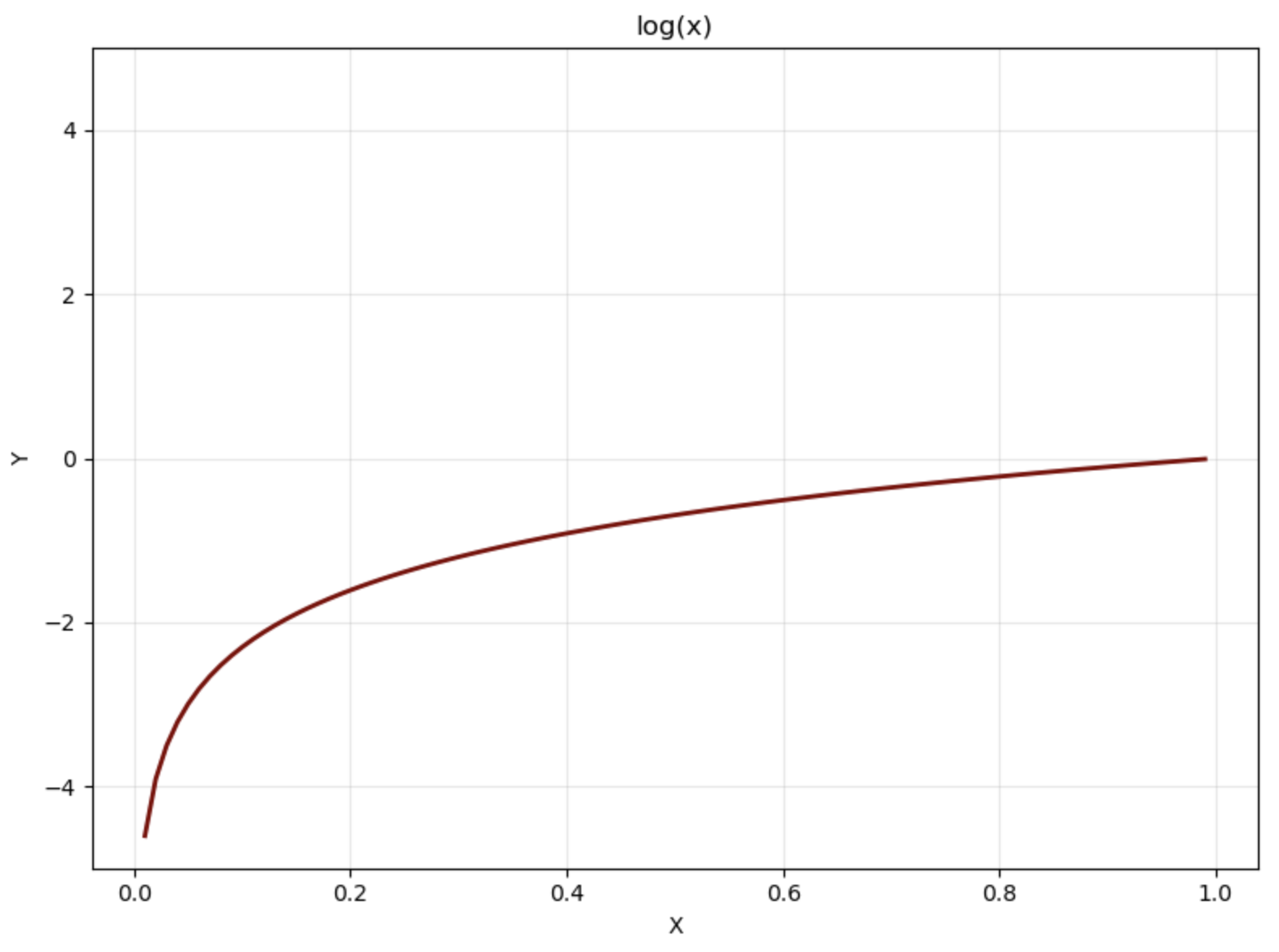
Fig. 1
Log probability graph
Log probability gives us a value of about when and a negative value when . This is not a suitable loss, as minimizing the log probability will give us fewer correct predictions rather than more correct predictions. However, if we take the negative log likelihood, this gives us a loss function that makes sense: higher values are assigned to less correct predictions, and near-zero loss is given when the probability for the correct token is close to one.

Fig. 2
Negative log likelihood graph
Therefore, by minimizing the negative log likelihood, you are maximizing the probability assigned to the correct token. This is a foundational concept in NLP and machine learning in general, so it's worth taking a minute to wrap your head around this process.
Cross-Entropy Loss
You'll generally see the actual loss used to optimize LLMs as cross-entropy loss.If we denote the target at each step by a one-hot vector and the model's probabilities by , the cross-entropy is
which reduces to because is one-hot. In other words, for next-token prediction, negative log likelihood and cross-entropy are equivalent.
In PyTorch, you can take the cross entropy through torch.nn.functional.cross_entropy. If you do not change the default arguments, this should be equivalent to using torch.nn.functional.log_softmax followed by torch.nn.functional.nll_loss.
Additional Resources
The background and exercises we provide are merely to give you the background necessary to implement pedagogically useful attacks and defenses in this course. If you are interested in exploring LLMs at a deeper level (which we encourage), below you can find a list of our favorite resources.
-
(Video): AI can't cross this line and we don't know why This video gives a beginner-friendly explanation of LLM scaling laws (Kaplan et al., 2020), which have motivated the development of modern LLMs.
-
(Video): Attention in transformers, step-by-step This video explains "attention," the key insight of the transformer architecture.
-
(Tutorial): ARENA: Transformers from scratch: In this tutorial, you will build a transformer from scratch, giving you foundational knowledge of every aspect of the architecture.