Prompt Automatic Interative Refinement (PAIR) & Tree of Attacks with Pruning (TAP)
This section has a series of coding problems using PyTorch. As always, we highly recommend you read all the content on this page before starting the coding exercises.
Motivation
In the previous subsection, we looked at token-level, white-box jailbreaks: attacks that require access to the loss of some model given an input and target sqeuence. But what if we want to jailbreak a model like ChatGPT, where we don't have white-box access? This requires a black-box algorithm that doesn't rely on access to model internals. One of the earliest and most famous algorithms that achieved this goal is Prompt Automatic Iterative Refinement, or PAIR (Chao et al., 2024). PAIR was additionally developed with the goal of improving the efficiency of token-level jailbreaks like GCG, which (as you likely experienced) require lots of queries and generally lack interpretability.
Prompt Automatic Iterative Refinement (PAIR)
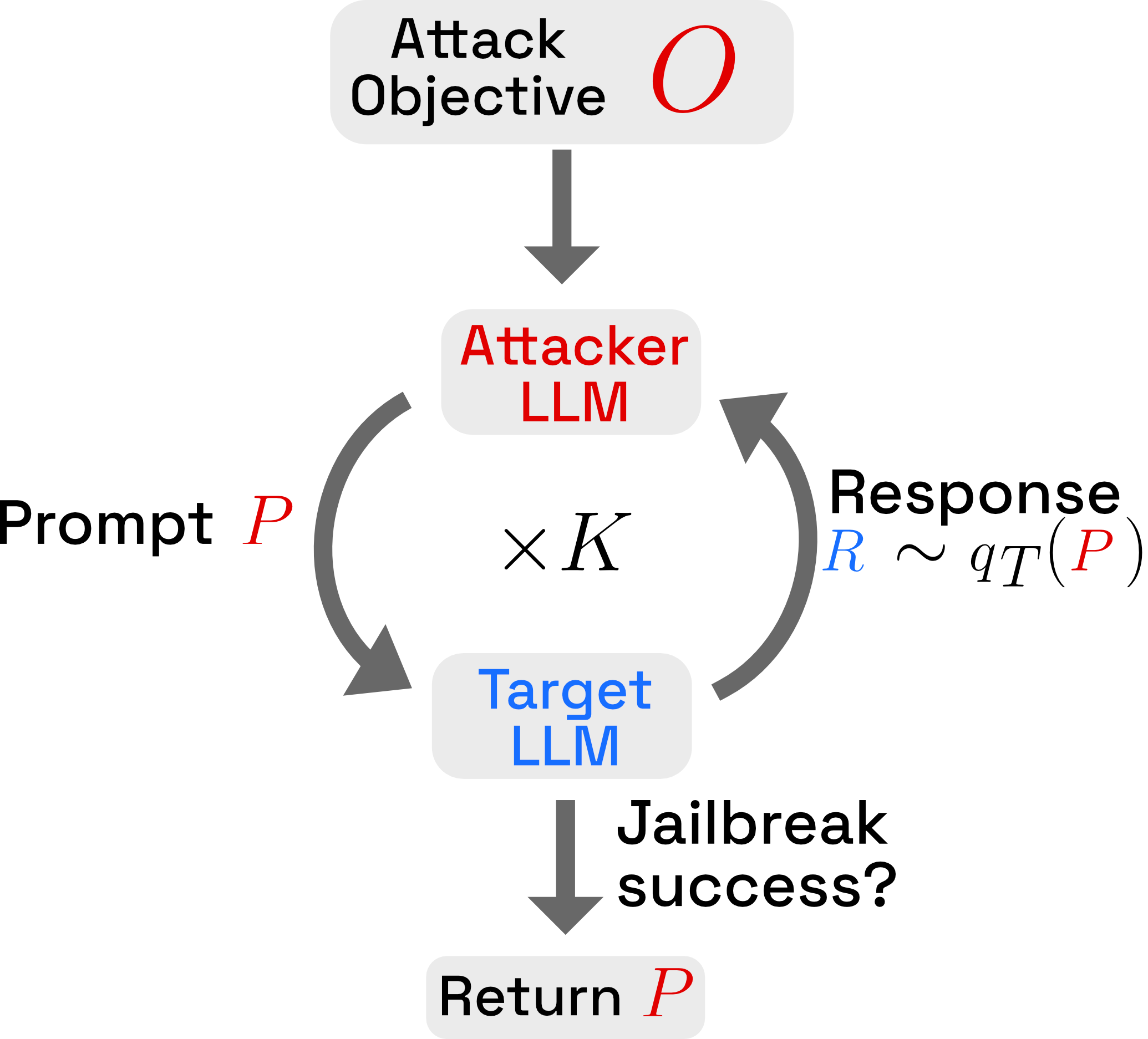
Fig. 1
Prompt Automatic Iterative Refinement (PAIR), modified from Chao et al. (2024)
The crux of the algorithm is simple: an attacker LLM tries to jailbreak a target LLM by iteratively refining a given prompt. Before looking at the psuedocode, however, we'll first define the notation used by the paper. Let represent sampling the response from model when queried with prompt . Let be a binary score from a judge LLM, with indicating that a jailbreak has occured and indicating that no jailbreak has occured given prompt and response . We additionally define model as the attacker LLM and model as the target LLM that model tries to jailbreak.
Now, let's look at the algorithm:
Algorithm: Prompt Automatic Iterative Refinement (PAIR) (Chao et al., 2024)
Hopefully it doesn't look too bad, but we'll still break it down. We start by initializing the number of iterations we'll run, as well as our objective , which is the restricted content our jailbreak is targeting. We send this objective to model and initialize the (at first empty) conversation history. Next, in each iteration, we sample a prompt from the attacker LLM given the context , sample a response from the target LLM given the prompt , and send the prompt and response to a judge LLM (this process is much easier to read in the pseudocode!). If the judge LLM returns that a jailbreak has occurred, our attack was successful and we can stop the algorithm. Otherwise, we add the prompt, response, and score to the context, then start the next iteration (or terminate, if all iterations have been performed).
In the original paper, the authors found that PAIR exhibited superior performance to GCG while requiring orders of magnitude fewer queries. Interestingly, they also saw better performance when PAIR was run with many more streams than iterations,i.e., performing many runs in parallel, refining each prompt fewer times. They evaluated PAIR specifically with streams and iterations. The authors do note, however, that PAIR did struggle to jailbreak Llama-2 and Claude versions 1 and 2, all of which are very robustly aligned models.
Tree of Attacks with Pruning (TAP)
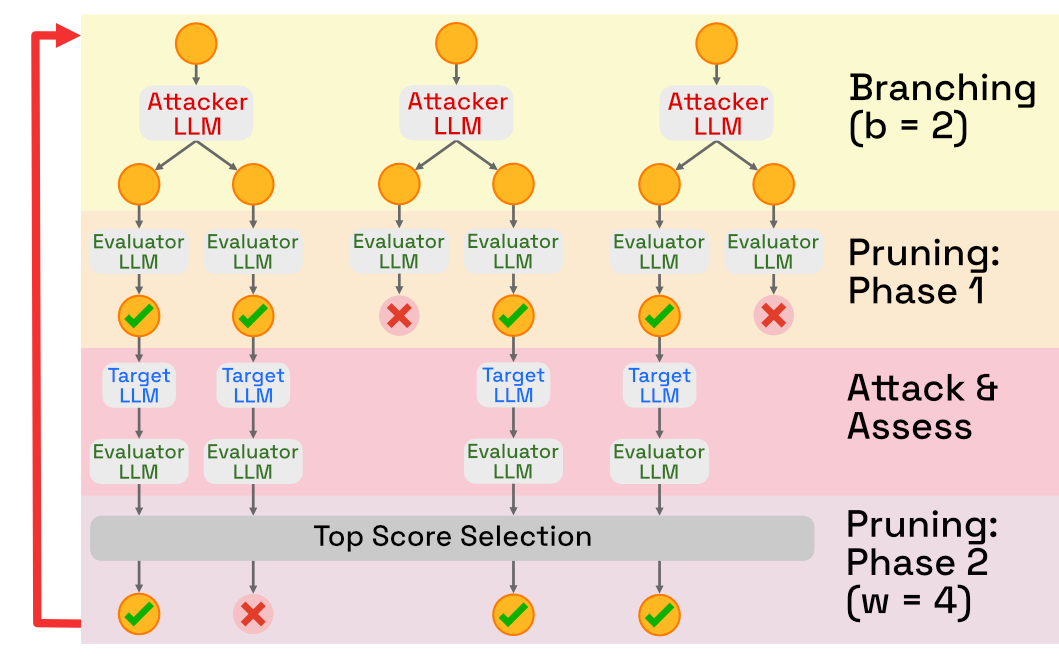
Fig. 2
Tree of Attacks with Pruning (TAP), modified from (Mehrotra et al., 2024)
Tree of Attacks with Pruning (TAP) (Mehrotra et al., 2024) was created as an improvement of the PAIR algorithm. Instead of a single refinement stream, TAP utilizes a branching system: in each iteration, the attacker model refines the prompt multiple times. Ineffective or off-topic prompts are then pruned, leaving only the best remaining prompts in the tree after each iteration.
Before introducing the algorithm, let us define , , and respectively as the prompt, response, and score corresponding to leaf in the tree. Additionally, let represent the conversation history of leaf . We also introduce a new function of the LLM, , which returns if the prompt is off-topic from the objective . Finally, the itself now scores prompts from to so that we better track the most effective prompts (this was actually done in the code implementation of PAIR, but not the pseudocode above).
Algorithm: Tree of Attacks with Pruning (TAP) (Mehrotra et al., 2024)
If you squint your eyes, you might notice that when , this algorithm is exactly the same as PAIR! The branching and pruning seem like minor additions, but by comparing TAP to PAIR and performing ablation studies, the authors showed that the branching and pruning improve jailbreaking performance while also decreasing the number of required queries to jailbreak.
The Takeaway
Both PAIR and TAP are fairly simple algorithms that are probably more effective than you might initially guess. Because AI security is such a new field, however, this is a very common occurrence. Simple ideas often work, so even if an idea you have seem basic, don't let that dissuade you from pursuing it.
Exercises
WIP